Design choices
- Tokenizer; why build the tokenizer the way you did?
- v1.0.0; why not make a v1.0.0 immediately?
- Spring; why use Spring?
- Writer; why is there not a CsvWriter?
- Architecture; why have the layering of CSV and not roll all into one layer?
- Error feedback; what is your thing with error feedback?
- Facade; why the Facade?
- Deep conversion; will CSVeed have deep conversion in due time?
- Splits and joins; will CSVeed have splits and joins in due time?
- Dry runs; will CSVeed support dry runs?
Tokenizer
Most CSV tools that I have seen use a mix of if-then-else logic and forward references for CSV parsing. Having tried these approaches myself as well, I find them error-prone and hard to maintain.
The goal of CSVeed was to have a tokenizer that read just one symbol at a time, without forward referencing. Also, I wanted it to determine its next state purely on the current symbol and state. I can imagine that people hate the huge switch-case construction (Cobertura does!), I can just as well imagine that people love it for its clarity and overview. I belong to the latter category.
v1.0.0
I believe a version 1 must have seen some time in the trenches before it can be elevated to that position. That means people must have used it, it must have run stable in production software and in general it must have existed for some time. Software that is immediately released as version 1 is not to be trusted.
I am aware that this may hamper the attraction of CSVeed, but I think the community and the prestige of the software is better served if the practice of steadfast growth to maturity prevails over a false sense of stability.
Spring
This was one of the harder decisions to make. Spring gave the project a headstart because it offers great out-of-the-box functionality for converting String objects to Bean properties.
The functionality of Spring that is used has to do with BeanWrapperImpl. One can use this class to wrap around a bean and set/get its properties sending/receiving only String instances. Spring has a number of PropertyEditor classes it supplies, which currently powers its popular Spring MVC web framework.
However, the Spring dependency comes at a price. Both Spring Beans and Spring Core are included in the dependency tree. The library is commonly used in web applications, although, it is undesirable for libraries. Therefore, the Spring dependency will in time be replaced with an innate conversion ability.
Writer
The focus of CSVeed is first and foremost on reading of the CSV. Writing to CSV is literally an afterthought, since it is much easier to write from a realiable structure (such as a Java Bean) to an unreliable one (CSV).
CSVeed caters to those people that need to get a grip on their CSV. It is aimed at the group of people that have experienced that reading CSV implies dealing with errors. Writing to CSV is flawless by definition and therefore without challenge.
In the future, a CsvWriter will be added to CSVeed, but there is no hurry to realize this. Error feedback has a much higher priority.
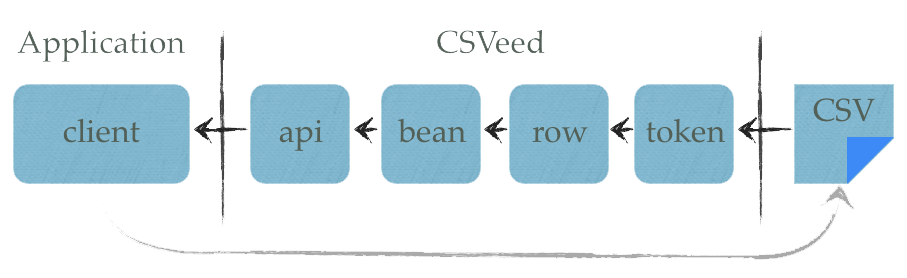
Architecture
Layering serves a crucial purpose as it helps to define system boundaries. Every layer in CSVeed aims to solve one particular problem.
CSVeed also offers three points of entry into the library. The easiest and recommend route is through the Facade, aka the api layer. The other two options are to plug directly into the bean or row layers. The token layer is not intended for direct access, though it would be possible.
Error feedback
Dealing with the reading of CSV is synonymous to dealing with errors. The 'structure' of a CSV file leaves a lot to be desired – there is no file that says what it structure will be like with XML. Users can (and often do) change CSV at will before sending it off to an import job. Anyone having worked with CSV for a prolonged period of time knows that errors are part of the essence of CSV files.
Errors that happen during the parsing process, in any of the layers, can probably be traced back to an error in the original CSV. Therefore it is of paramount importance that the library reports back on the original error, not just the error that it it generates in a particular layer.
Also, errors that happen after the parsing process has completed, can probably still be traced back to the original CSV file. CSVeed can currently only report back on errors that it encounters itself. In the near future, it will be made so that clients can use the CSVeed context to refer back to the original CSV cell where the error occurred.
Facade
The Facade has been inspired by JavaCSV. This library has just two classes; a writer and a reader. Every bit of logic has been pushed into those two classes. It must be a nightmare to maintain those classes.
The user, on the other hand, is given a treat; it gets the simplest possible interface to interact with the library. The community has shown itself very enthousiastic over the simplicity of JavaCSV.
CSVeed takes a different route. The maintenance mess of just two classes has been evaded, while the user still gets a simple interface. The way this is done is by setting up a Facade that shields the underlying complexity.
Deep Conversion
Deep Conversion is the ability to build up a uni-directional graph of entities from a CSV file:
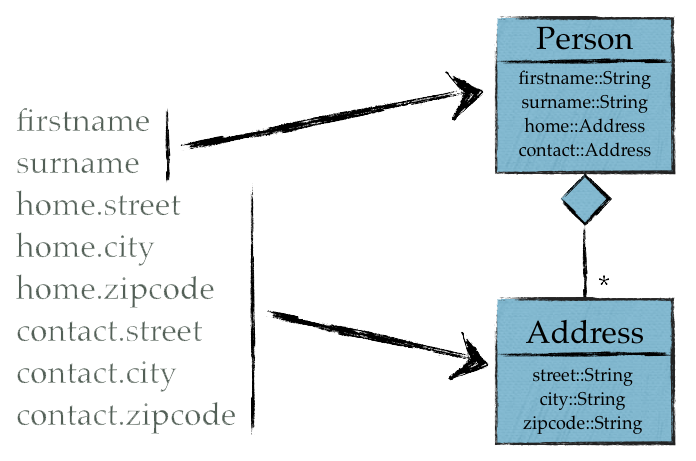
Deep Conversion is currently not support by CSVeed, this this is planned for the near future.
Splits and Joins
A split is the ability to split a single cell into multiple Bean properties:
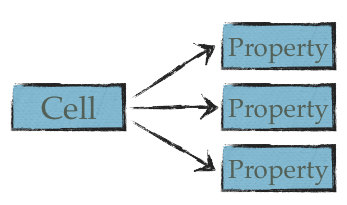
A practical example would to split a cell like, for example, "€ 50" into separate currency and amount.
A join is the ability to join multiple cells into a single Bean property:
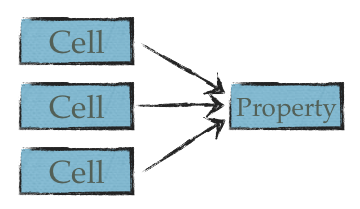
A practical example would be to merge first name and last name into a single property called full name.
The main challenge with splits and joins is basically to supply a structure where clients can create converters for an array of Strings or BeanProperty instances, so that symbols can either be inserted or removed.
CSVeed currently does not have split and join capabilities, though this is planned for the near future.
Dry runs
A dry run is a crucial concept in processing CSV files. CSV files are processed up to the point that enough is known to generate a comprehensive error report, without committing the data to its next stage, such as being persisted to the database.
The way a dry run must work, is that it returns a list of Bean with their original CSV context and a comprehensive list of errors, so that the client can post-process the beans and add their own errors to the list. The entire list can then be fed back to the owner of the CSV file.
This functionality is currently not supported by CSVeed, but will be in the near future.