Architecture
The basic architecture consists of four layers, which correspond with the package structure:
- api; Facade for bean and row, used to have a single class for interacting the underlying layers
- bean; layer responsible for translating rows to Beans.
- row; layer responsible for translating tokens to lines and lines to headers and rows.
- token; layer responsible for parsing the CSV file one symbol at a time and translating those to tokens and lines.
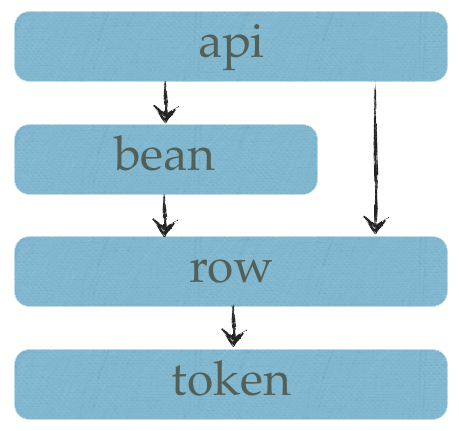
Furthermore, there are two auxiliary packages:
- report; structure for reporting back errors with references to the original CSV row
- annotations; various annotations for instructing the bean, row and token classes.
api
Design goal: a single Facade for interacting with the underlying layers, intuitive in usage and operation
CsvClient joins both BeanReader and LineReader, and their respective instructions classes in a single class. Developers making use of the Facade now only have to deal with one class to drive the process.
bean
Design goal: user-friendly (ie, low-maintenance for user) way of converting CSV rows into Beans
This is where Rows are converted to Beans. This process makes use of the original Mapping strategy, which is either column index or column name based:
- column index mapping; used by default, executed by the ColumnIndexMapper. Maps found cells to Bean properties by their index of the column in the CSV file.
- column name mapping; executed by the ColumnNameMapper. Maps found cells to Bean properties by the header name of the column in the CSV file.
All mappable cells are converted to the Bean property using Converters. Custom Converters can be configured as well.
row
Design goal: collecting headers and rows, while maintaining links to the original line text for later reference
Lines are read in their bare form. When headers are used, the first read line will be converted to a Header, whereas the others are all Row instances. The layer takes into account the needs for jumping to the start line, and skipping empty or comment lines. Only valid lines are offered for conversion to a Header/Row.
Whenever a line is read in the row layer, it is stored together with information on its original CSV line. This information contains two important aspects:
- start and end of columns
- non-printable characters made printable
Users can directly read Rows, with their Header and extra information.
token
Design goal: most versatile and effective way of tokenizing CSV files, without forward reading, one symbol at a time
The tokenizer is made on a state machine. The state machine gets one symbol at the time and on the basis of its current state, it can determine its next state. The state machine is capable of saying whether tokens must be returned (ie, a cell has been read), or lines are finished. The states are fixes and cannot be configured. Most meaningful symbols (except SPACE and END-OF-FILE) can be configured.
report
Design goal: ability to trace back errors on a property to the original cell in the CSV line, even after the conversion process has taken place
When an error occurs, the exception can be fed with exact details on the position of the cell in the CSV line, meaning that lines can be printed showing precisely the location of the error.
annotations
Design goal: an intuitive way of defining parsing and mapping instructions directly associated with the Bean class and properties
Annotations have a big advantage of the declarative model, which is that the elements they describe are hard-coupled with the instruction. The declarative model on the other hand, is a soft-coupling, more prone to failure, such as name changes that go unnoticed.
Annotations and the declarative model are mirrored, so that everything that can be declared with annotations can also be declared programmatically and vice versa.